Anthropic's year of banned hackers: how 832 accounts broke MITRE ATT&CK
Anthropic analyzed 832 accounts it banned for malicious cyber activity over 12 months and found the share of medium-or-higher risk actors jumped from 33% to 56% — a 1.7× increase. The deeper finding: the standard signals used to assess threat actor sophistication (technique count, interface choice, prompt complexity) have all broken down. The most dangerous actors are defined not by what they ask AI to do, but by the autonomous orchestration scaffolding they build around it — and MITRE ATT&CK has no technique ID for that.

In the first six months of Anthropic's study, 33% of the threat actors it observed using Claude maliciously were classified as medium-risk or higher. In the second six months, that share had jumped to 56% — nearly 1.7 times as many actors crossing the threshold that security teams use to escalate a response. 1
That figure is the organizing fact in a report Anthropic published on June 3, 2026, which does something unusual in the AI safety genre: it takes a year of real banned accounts, maps their actions line by line onto the MITRE ATT&CK framework, and then argues the framework itself needs to change. The report draws on 832 accounts banned between March 2025 and March 2026, accounting for 13,873 observed attacker techniques across all 14 ATT&CK tactics. 2
What 832 banned accounts reveal
Every month, Anthropic's Threat Intelligence team reviews accounts flagged for violations of its Usage Policy. For this study, the company selected the subset where it had enough behavioral detail to extract tactics, techniques, and procedures (TTPs), then mapped each one to MITRE ATT&CK v18.
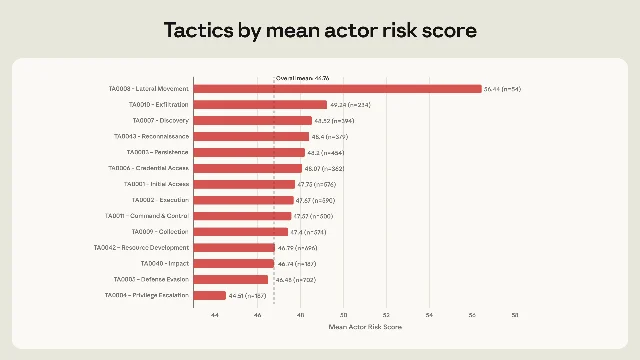
The result is 13,873 individual technique observations — the largest dataset of its kind that has been published. To turn that into something analysts can use, Anthropic developed a scoring system called ARiES (AI Risk Enablement Score), which rates each actor from 0 to 100 across three additive dimensions: Threat (intent, sophistication, evasion tactics), Vulnerability (the model's capacity to enable the requested harm, weighted by interface type), and Impact (real-world consequences attributable to AI assistance). 2
The choice to add the three components rather than multiply them is deliberate. A multiplicative model — the standard in classical cyber risk equations — zeroes out the score when any one dimension is absent. An inexperienced actor who accidentally produces a working wormable exploit would score zero on intent and thus zero overall, even though the model just provided significant uplift to a potential attacker. The additive model preserves each signal independently so partial attack-enablement patterns remain visible. 2
With ARiES, Anthropic can classify actors into low, medium, high, and critical tiers — and that classification is what showed the 1.7× increase in medium-or-higher actors over 12 months.
Loading chart…
The anatomy of AI-assisted attacks
What most actors do
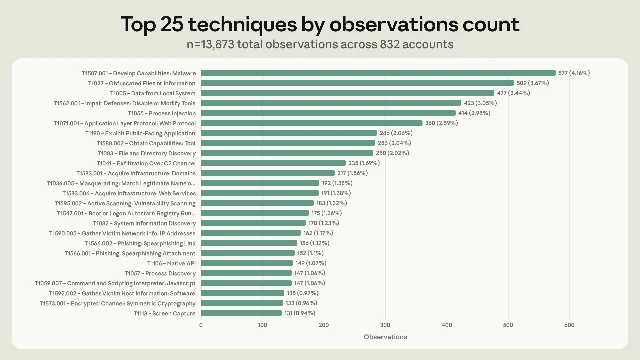
The most common use of AI in this dataset is exactly what most security teams expect: capability development. 560 of 832 actors (67.3%) used Claude to write or refine malware, obfuscate payloads, or build scaffolding for attacks. The second and third most common technique families are obfuscation (64.7%) and impair-defenses (54.9%). Defense evasion alone accounts for more observed activity than all post-compromise stages combined. 2
This broad population of actors uses AI as a force multiplier for preparatory work — writing better malware faster, generating more convincing phishing lures, encoding payloads in ways that evade signature-based detection. They are, in the report's framing, building better tools before they get into a network.
What high-risk actors do differently
The 10% of actors with the highest ARiES scores share a different pattern. They concentrate their AI use not on pre-attack tooling but on post-compromise operations: lateral movement, credential dumping, web shell deployment, account discovery inside compromised networks, and data exfiltration. These are the hands-on-keyboard techniques that used to require the most technical skill to carry out in a live environment.
The numbers are stark. Actors who used Claude for lateral movement had average ARiES scores 10.5 points above the dataset mean of 46.8 — no other single technique came close to that predictive power. The techniques most concentrated among high-risk actors (remote services via SSH/SMB, valid account exploitation, OS credential dumping, archive collection, and web shell deployment) were three to five times more common among the top-risk cohort than across the full population. 2
A directional shift is also visible within the study period. Between the first and second halves of the year, Anthropic observed an 8.9% increase in account discovery attempts and a 6.2% increase in automated exfiltration, alongside an 8.6% decrease in phishing (initial access) and a 12% decrease in capability development. 2 The population as a whole is moving deeper into the kill chain.
Why the old risk signals no longer work
Security analysts have traditionally distinguished low-skill actors from high-skill ones using three proxies: how many distinct techniques they use, how technically sophisticated their prompts appear, and which interface they prefer (chat vs. API vs. agentic coding tools like Claude Code).
All three have broken down.
The median actor in this dataset deployed 16 distinct MITRE ATT&CK techniques — breadth that, five years ago, would have indicated a well-resourced, technically mature operation. But the most skilled actors in the dataset averaged only about 20. The gap has collapsed. Technical sophistication, when measured by prompt complexity and tool depth, correlated with remaining risk components at only r = 0.28 after removing the circularity. And 80% of the malicious actors in the study misused Claude Code — the agentic coding platform — making it so common that interface choice tells analysts nothing. 2
What that means in practice: an analyst looking at a new threat report that mentions "used Claude Code, deployed 18 different techniques, sophisticated prompt structure" now has essentially no signal about how dangerous the actor actually is. The data suggests they should instead be asking whether the actor applied AI to post-compromise operations — and whether the actor built scaffolding that could chain those operations together autonomously.
The second question is harder to answer, because the architecture of autonomous orchestration leaves almost no trace in the MITRE ATT&CK framework.
The gap in MITRE ATT&CK
MITRE ATT&CK is how threat intelligence gets shared. It is the taxonomy that fills SIEM dashboards, informs red team playbooks, and lets analysts at different organizations discuss the same attack in the same language. It currently covers 14 tactics and hundreds of techniques.
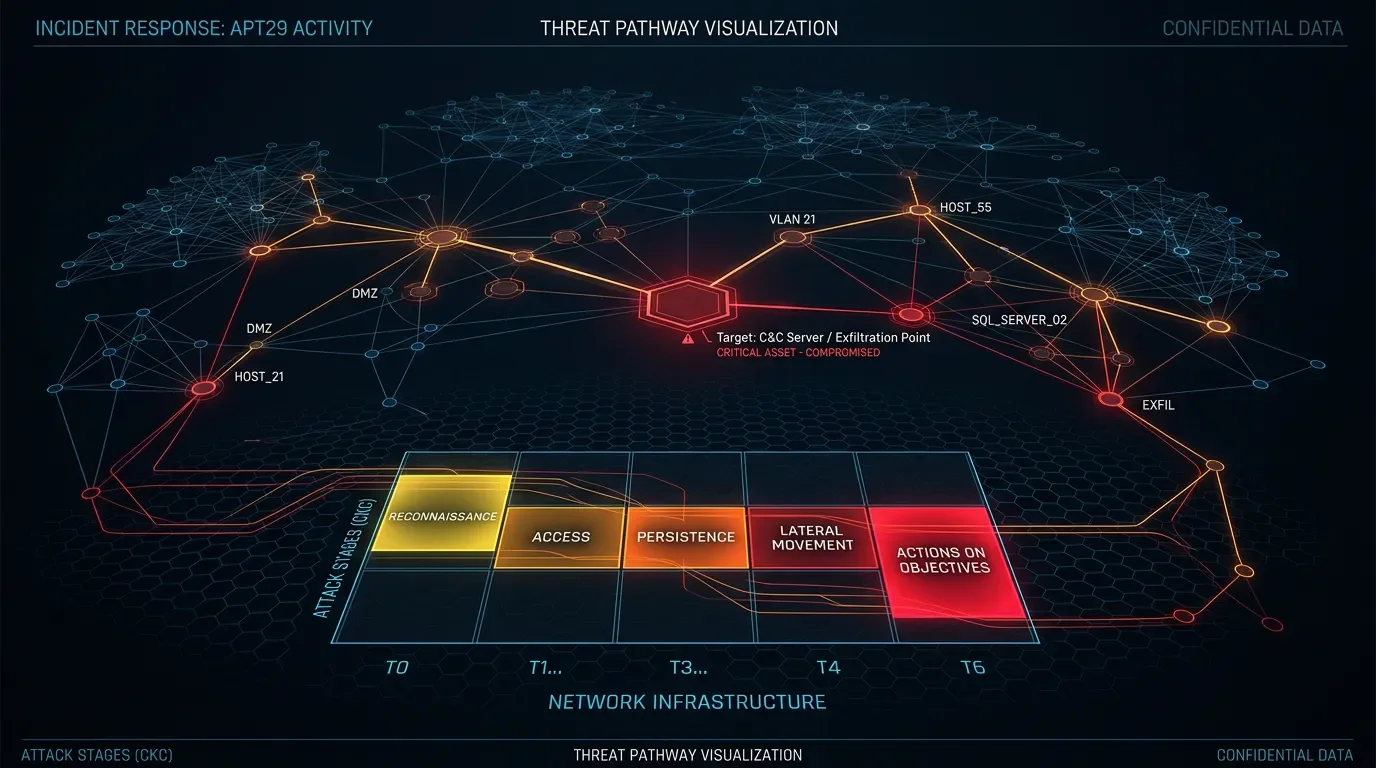
But it was built to categorize human actions. When an AI agent runs autonomously through an attack kill chain — executing commands, exploiting vulnerabilities, dumping credentials, making tactical pivot decisions, exfiltrating data, and documenting itself for the next stage — each individual action may map to an existing ATT&CK ID. What has no ID is the orchestration layer itself: the AI's ability to sequence those actions without human intervention, make real-time decisions about what to do next, and run continuously at machine speed. 1
The state-sponsored espionage campaign that Anthropic disrupted in November 2025 makes this concrete. A Chinese state-sponsored threat actor manipulated Claude Code into attempting infiltration of roughly 30 global targets — tech companies, financial institutions, chemical manufacturers, and government agencies — with human operators intervening at only 4 to 6 critical decision points per campaign. 3 The AI made thousands of requests at peak, often multiple per second, conducting reconnaissance, writing exploit code, harvesting credentials, and documenting stolen data faster than any human team could have matched.
When Anthropic mapped that campaign onto MITRE ATT&CK, it used 30 techniques across 13 tactics — comparable to many medium-risk actors. The attack scored 100 on ARiES, the maximum. 1
That is the gap. A maximum-risk attack looks medium-risk if you only count ATT&CK IDs. The taxonomy that modern threat intelligence relies on has no way to express the difference between "a human used AI as a tool to do 30 things" and "an AI agent autonomously orchestrated 30 things with minimal human input."
Defenders, classifiers, and MITRE
The report is not primarily descriptive — it is trying to change what the security industry measures.
On the classifier side, Anthropic has updated the detection systems built into Claude to flag the behavioral indicators uncovered in this analysis: specifically, the high-risk post-compromise techniques correlated with elevated ARiES scores. The company also expanded what it calls "probe" detections to cover the orchestration-layer signals that standard technique counting misses. 1
On the framework side, Anthropic says it is in discussions with MITRE about how ATT&CK might add categories for AI-enabled autonomous behaviors. The interactive LLM ATT&CK Navigator that accompanies the report is designed to be a working prototype — a visualization that shows where in the ATT&CK matrix AI-enabled misuse clusters, as a starting point for the conversation about what new IDs are needed. 2
The Verizon partnership is the other delivery mechanism. Some of these findings appeared in the 2026 Verizon Data Breach Investigations Report, giving the data reach into the incident response community that reads DBIR as a primary signal source. 1
What the report leaves open is whether the framework evolution can keep pace with capability evolution. Anthropic's own Mythos Preview model, evaluated in a companion red team post, already demonstrates cyber capabilities at a level approaching the most skilled human researchers. 2 The 832 accounts in this dataset were misusing generally available models. The pattern they show — a population-wide shift toward autonomous, post-compromise AI operations — is a preview of what happens when the population gets access to more capable models.
The tally so far: 13,873 technique observations, 482 unique ATT&CK techniques, all 14 tactics covered. The thing that made the most dangerous actor score 100 still has no technique ID.
Add more perspectives or context around this Post.